4 Things We Can Learn About Conspiracy Theories and Model Flexibility
A Conspiracy Theory is Like a Bad Model
A few years ago my mum became very susceptible to suggestion, and made friends with a guy who was really good at speaking about nonsense with the authority to make it sound true. Listening to him sent her down a conspiracy theory rabbit hole, of which I had to experience second hand. Our interactions ended up boiling down to mum sending me a 20 minutes Youtube video about aliens building the pyramids, then I would wait the appropriate amount of time and send a text that said “Wow, what an interesting perspective”. I always hoped it would end the conversation and we could talk about something else, but instead it tended to inspire a paragraph long text rant about how the government was hiding free energy from us, and an 11 year old Texan genius had discovered the plot. When I think of flexible methods, I often have flash backs to that period of my life. Not because high degree polynomials were built by ancient aliens or an 11 year old genius but because we can use the pitfalls of conspiracy theories to understand the difference between flexible and inflexible methods.
What Is Flexibility.
I think of flexibility as the trade off in capturing the “local” and “global” trends in our data. An inflexible model will capture the global trend of the data, but any relationship between our variables is lost. If we instead choose a flexible model, we are focusing on the local trends and giving our model a better chance at capturing variable relationships, at risk to overfit to the sample. Flexibility has key interactions with 4 other elements of our model: the sample size, dimensionality, assumptions about the function, and irreducible error.
1: Outrageous Claims Need Outrageous Evidence
My mother is a “bit eccentric” to put it mildly. In the last few months, to only name a few things, she has bought a fire truck to start mud-crabbing (pictured below), bought some goats because the garden is a pain to manage, and turned the pool into a “fish Club Med” where she collects wildlife from the local creek and feeds them McDonalds for breakfast. From expulsions to arrest warrants, to the man she drank goon with at the beach who now lives in our house, the stories are endless. Despite this, never in my life had I ever been called a liar for telling them (the first time was at university orientation). People at my school had grown used to it, they had met my family and heard years worth of stories so I had a wealth of evidence to normalise my claims. Strangers didn’t have that, and so they didn’t believe my outrageous (completely true) tales. Similarly in statistics, if we want a complicated model we will need a large sample size to back it up.

Why Flexible Models Need a Bigger Sample
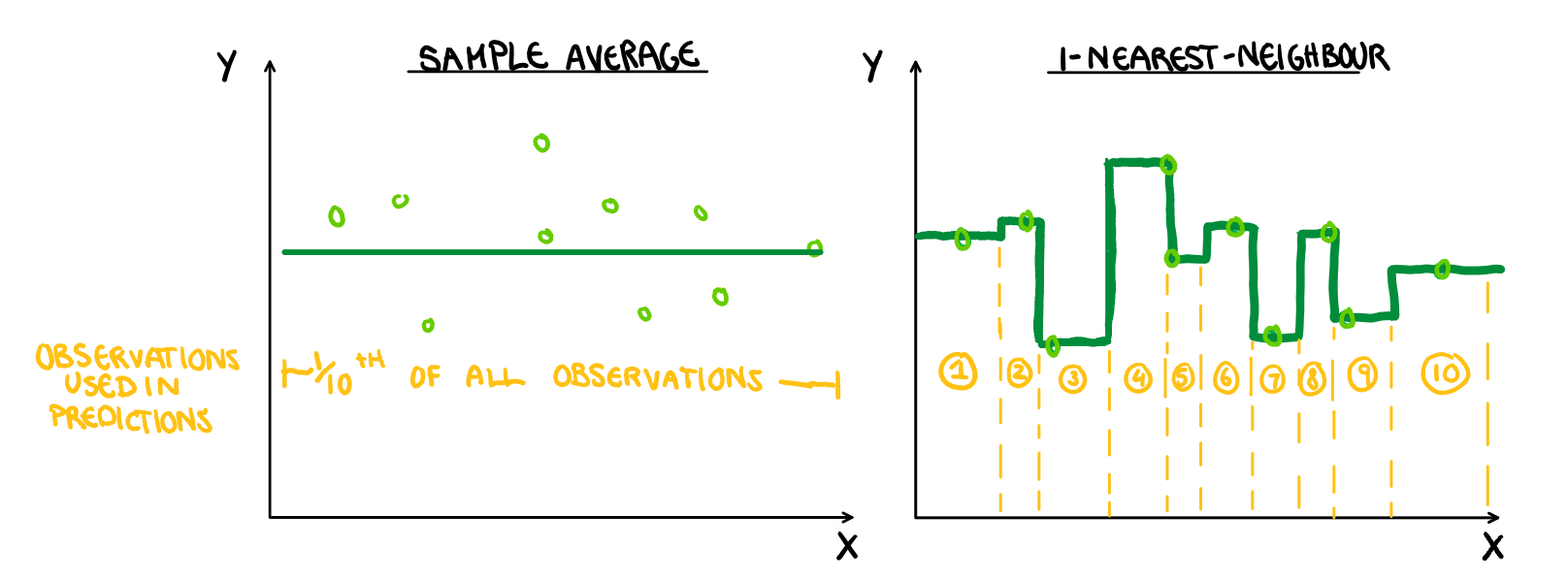
In general, the larger your sample size, the more likely it is you have captured the “true relationship”. If you are increasing the number of parameters to estimate (not literally for non-parametric models but the idea carries on) without increasing the sample size, we are in effect decreasing the “sample size” for each of the estimated values, and thus decreasing the reliability of our model. Placing more weight on all the observations in calculating our estimates, means we are increasing the influence of outliers and unrepresentative samples. We can either have observations contributing to a large area but averaged over many observations, or over a small area where our estimates are averages over fewer observations. For example, if we have 10 observations and predict using the average, each observation contributes to 1/10th of the prediction, if we use 1-Nearest Neighbour, each prediction is only backed up by a single observation (illustrated below). Highly flexible models can be, and sometimes are, the appropriate choice to model a relationship, we just need a large sample to justify it. Outrageous claims need outrageous evidence.
2: The Internet - Deliverer of Facts and Local Cult Meet Ups
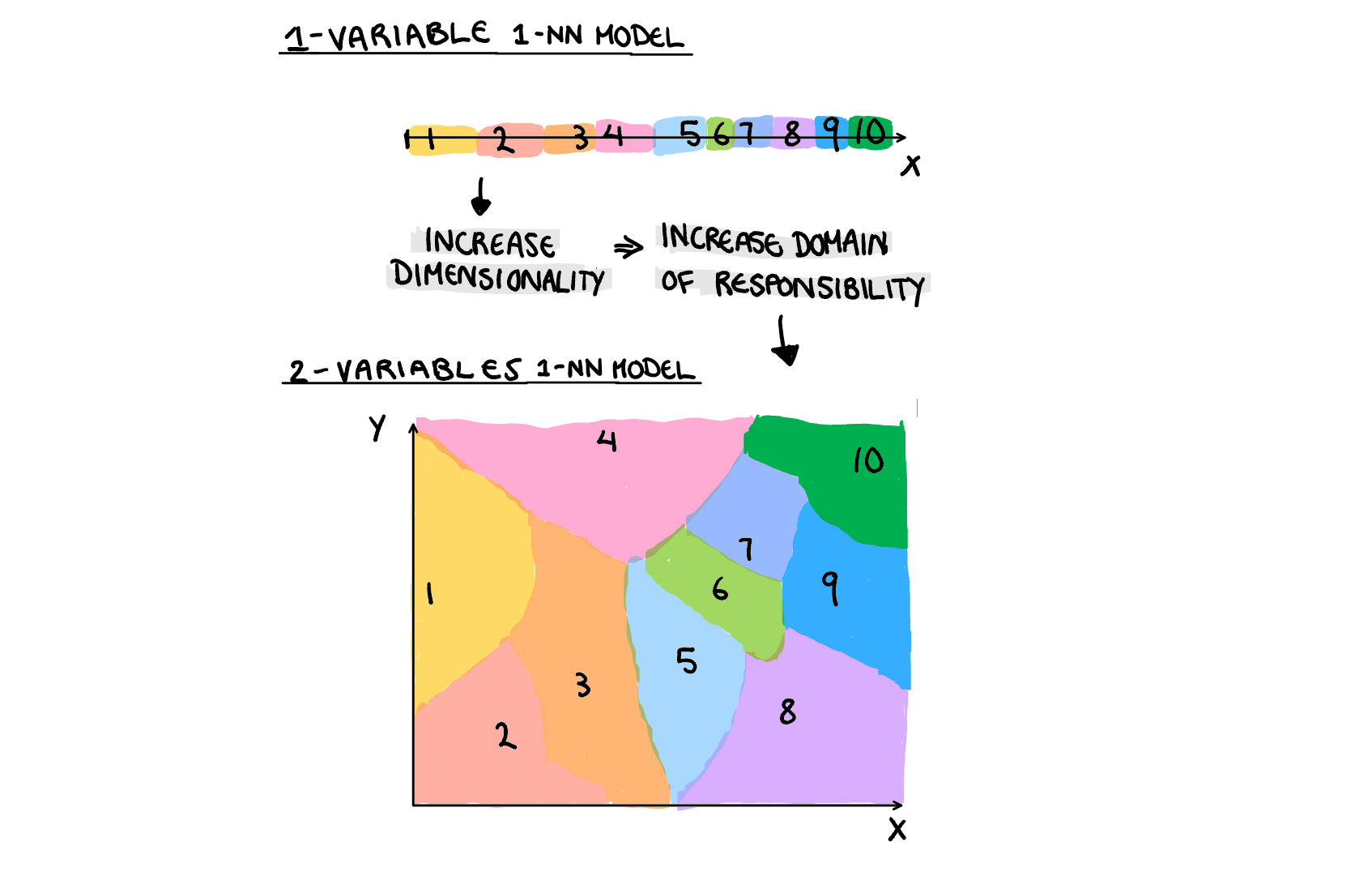
The introduction of the internet was the age of new information. Conspiracy theories were on their way out, now anyone can use their phone and find the facts in seconds. Or can they? What I unfortunately discovered when mum got involved with conspiracy theories, is that for every website with legitimate information, there are 50 that don’t. The sheer vastness of the internet means that whenever we expand our search for hidden truth, we are just as likely to discover falsities. This is a useful illustration in dimensionality.
Flexible Models Are Hurt More By Additional Parameters
Dimensionality interacts with the flexible vs inflexible models in two ways. The first is that in some occasions adding dimensions can literally be seen as making the model more flexible. Think of adding a squared variable to a linear regression to make it quadratic, we have made the model more flexible by adding a dimension. The second way it interacts with our models, is by increasing the distance between observations, and thus the amount of input space each observations needs to be used for. To get technical, each additional parameter makes the area each observation is responsible for increase exponentially. Just like how increasing flexibility increases the “weight” of observations by localising their impact on the model, dimensionality makes the total “area” bigger, and so it does a similar thing. Sometimes the relationship between our variables needs to be modeled with a highly flexible model, and so we need to keep this interaction between flexibility and dimensionality in mind so the variance doesn’t get out of control.
3: Capitalism - The Gateway Conspiracy to Lizard People
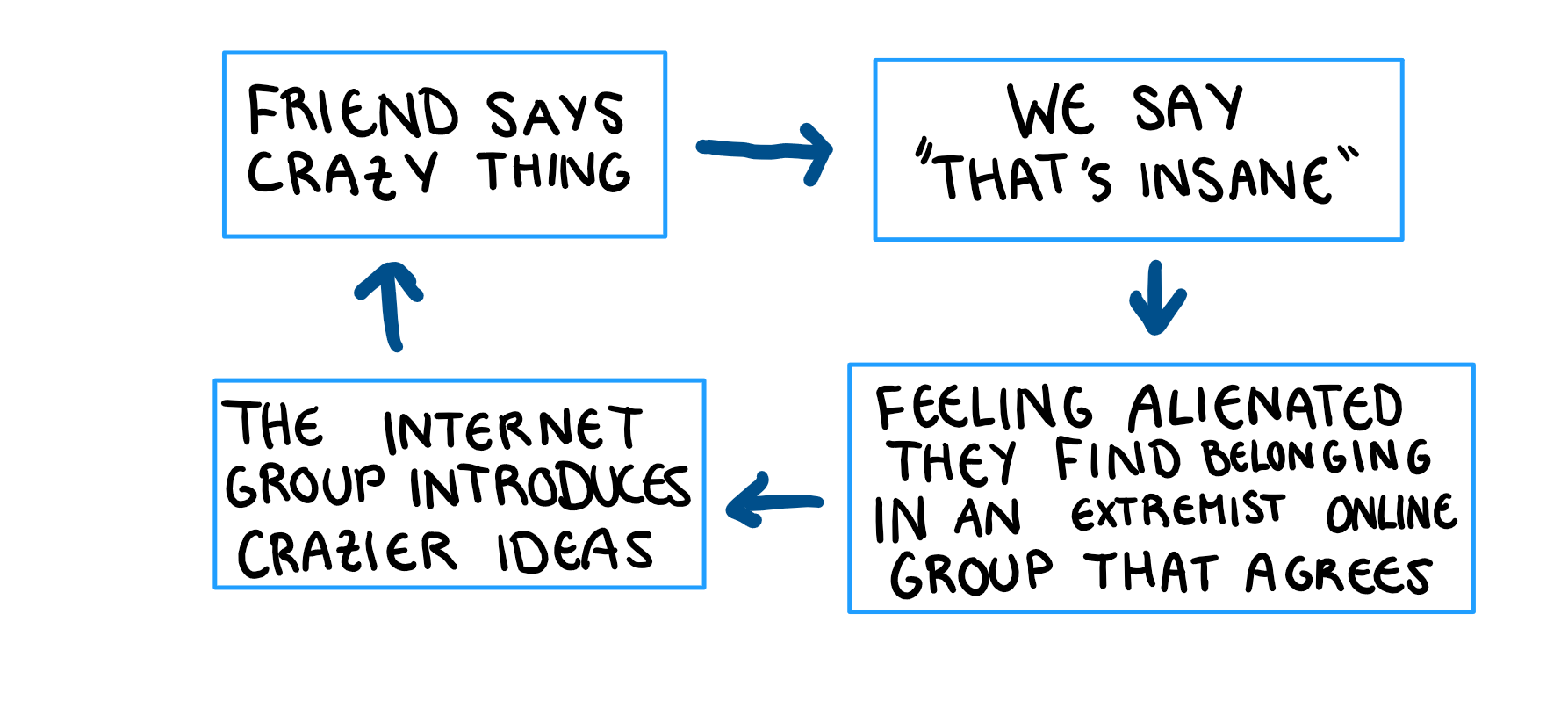
Nobody suddenly wakes up in the morning, looks in the mirror and says to themselves “Yes, today is the day. Today is the day I start believing in the lizard overlords.” I believe the process is more nuanced than that. Just like the “SayNoToPeerPressure” acting troupe who’s dreams I got to watch die in the comfort of my high school gym, I’m about to push the idea of gateways. From my personal experience, the process of becoming involved in conspiracies looks a little something like this:
My point is that ideas that hinge on something already well established in society are easier to swallow than those that aren’t. That is not to say entirely new theories must be wrong, but rather that they are harder for people to immediately understand and they are also more likely to be too out there for the general population to get on board with. I think of parametric and non-parametric models in a very similar way to how people think of capitalism vs lizard people conspiracy theories.
Non-Parametric Models Are Usually More Flexible, But Not Always
Parametric models construct our function by assuming its type, and then estimating the best model within this range. Non-parametric models do not make any assumptions about our model’s form, but rather try to fit to the general shape of the data. Parametric and Non-parametric does not directly translate to flexibility; they both have the potential to produce a very flexible or inflexible fit. For example, a constant polynomial and a K-NN model where K=N would both predict the average response (the most inflexible model we can get). Rather, just like dimensionality, non-parametric models can fall into the same pitfalls as flexibility, and so the limits of our dataset should be kept in mind. By their nature, non-parametric models are more susceptible to variance from changes in the sample, as the sample is the only thing the model is using to make its predictions. Therefore, they are more likely to overfitting than parametric models and are usually more difficult to interpret. These features mean that in general non-parametric models are more flexible, simply by their nature, however they are still have the potential to be inflexible.
4: There are Always Going to Be Loonies on the Internet
We can all spend our entire lives trying to convince everyone on the internet that they are wrong, but at the end of the day, we live in a complicated world, with complicated people, and there are always going to be loonies on the internet. Rather than dreaming of a world where everyone knows everything all the time, the system should just be to manage the chaos. The important life skill to learn isn’t that everyone needs to be corrected, and to focus on the nutters, but rather enjoy the fact that the majority get most things right, most of the time. Socrates might disagree with my idea on majority votes but you win some, you lose some.
You Will Always Have Irreducible Error and It’s Size Matters
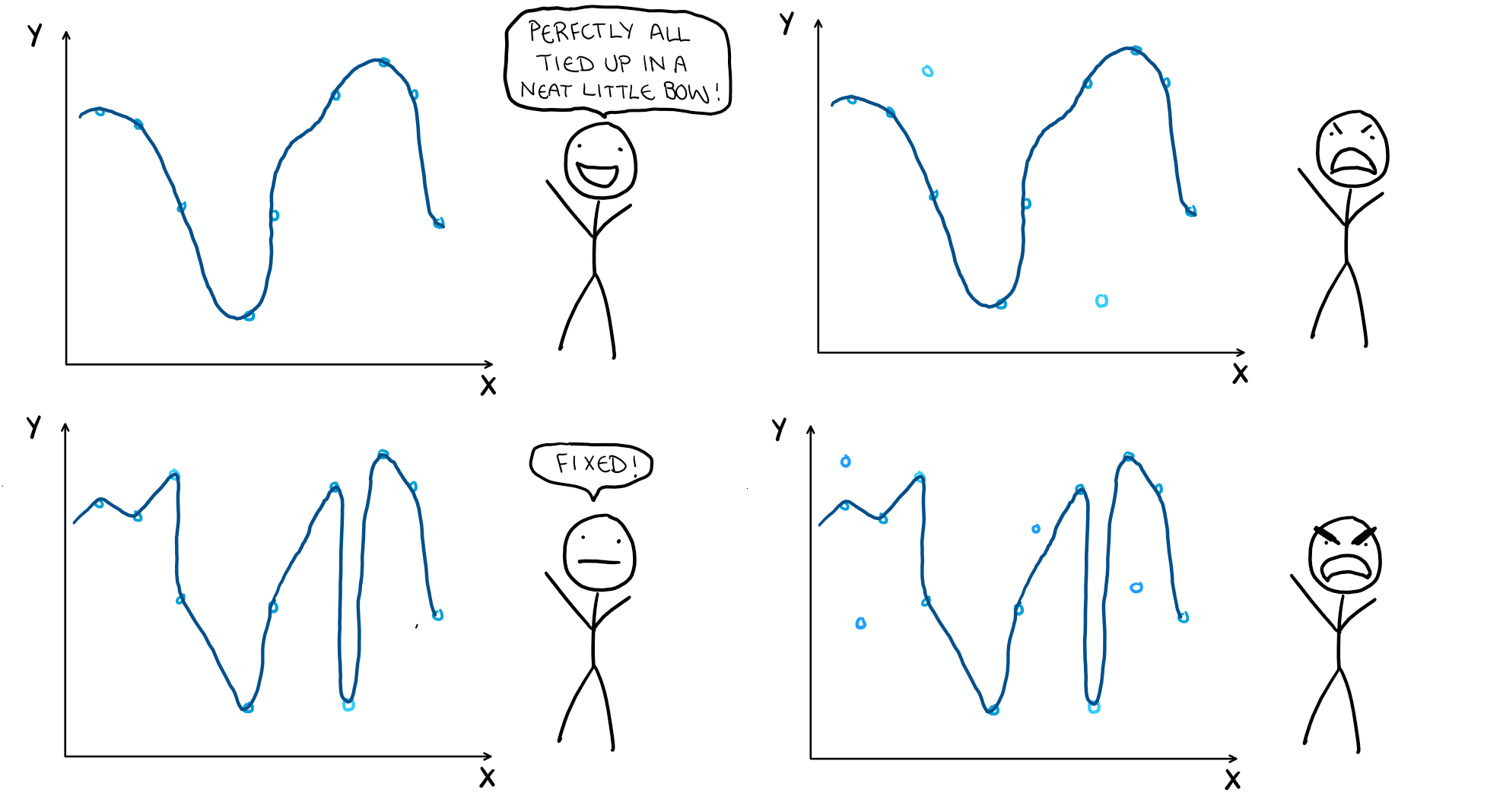
Obviously we can never have a perfect prediction since we are working with random variables. We can make our models more flexible to try and account for as much of the error as we can, but if we do, we might end up missing the underlying system entirely. No matter how flexible our model is, we will never have perfection thanks to our irreducible error (an attempt at making one is illustrated below). The interaction between flexibility and irreducible error comes from its size. A large irreducible error means the general shape change more drastically between samples, while a small one means our samples will remain consistent. Just like dimensionality, assumptions about our model, and sample size, this is just something that needs to be kept in mind as it has a strong interaction with the flexibility of our model, and the error from variance.
To Conclude
Don’t let your mum hang out with weirdos, and treat conspiracy theories and overly complicated models with scepticism.