Criminal Statistics in Baby Murder Court Cases
My Experience with the Legal System
I have had my fair share of run-ins with the legal system. Probably more than someone my age should have. Here are my three favourite interactions so far:
- A guy on acid threw a rock through my window at a music festival and they found him an hour later running around a field and screaming “I’m the richest man in the world”
- My landlord snapped when he was at our house doing maintenance, jumped the fence and assaulted our neighbour who now has a restraining order against him
- My parents tried to sue my high school after I was expelled for giving a speech about the private school system at a public speaking competition
The point here isn’t to talk about my interactions with the law, but rather to show that I have seen a police officer at least once, so I’m definitely well versed enough to critique our complicated legal system. So well versed in fact, I’ll do it while explaining the difference between samples and populations. For the sake of keeping it interesting, lets narrow this weeks side topic even even further to “court cases where the mother was convicted of killing her infant baby thanks to faulty science and circumstantial evidence”. At this point I could be spinning a wheel to decide these side stories with how much they actually have in common with machine learning.
Part 1: Meadows Law and The Difference Between a Population and Sample
How Bad Maths Ruined Sally Clark’s Life
In 1999 Sally Clark was trialled, and convicted for the murder of her two infant sons. Both had died from Sudden Infant Death Syndrome (SIDS), which is basically the medical term for “I don’t know man, sometimes babies just die”. A key piece of evidence for her conviction was the testament of Professor Roy Meadows, who claimed that the chance of two children of an affluent family dying from SIDS was 1 in 73 million. He found this number by squaring the probability that a child in similar circumstances died from SIDS (1 in 8500). There are two major problems with Meadows Law; the prosecutors fallacy and assumption of independence. Meadows law confuses the probability of “cause given effect” with “effect given cause”. The probability that a single baby dies from SIDS is 1 in 85000, but that wasn’t the case here. Sally Clarks kids had all ready died, and so setting the population to be every baby, alive or dead, would be misleading and incorrect. The population for finding out how likely both kids were to have died from SIDS needed to be compared to other causes of death, by using babies that had died as the population. Meadows law is an excellent example in the importance of a correctly defined population and sample.
Defining The Population and Sample
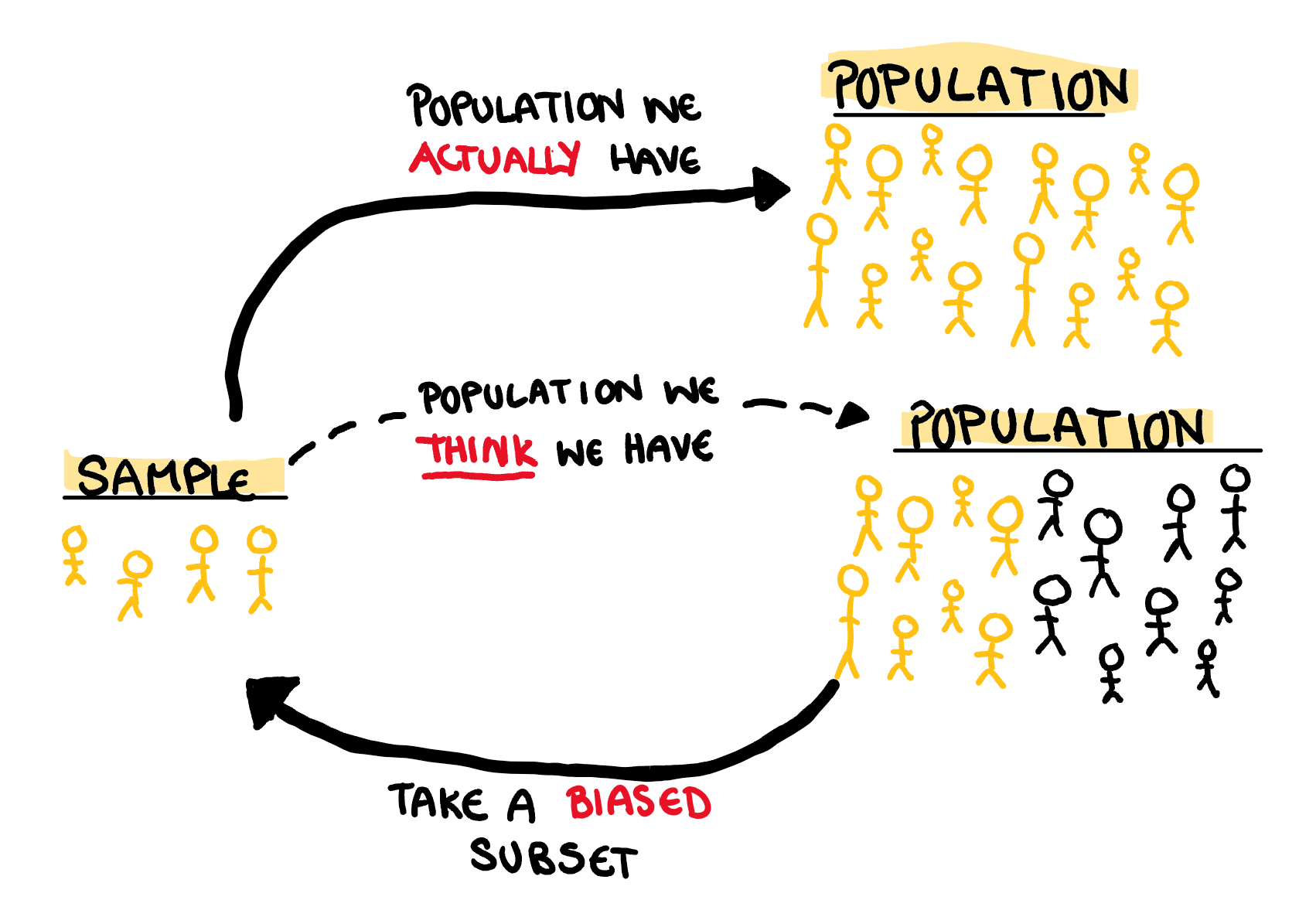
Samples and Populations are two peas in the statistical pod and their relationship is quite simple. Populations define the group we want to understand, and a sample is a random subset of that group which we use it to understand the population. Actually that explanation is a little circular, let me draw it to make it easier to see.
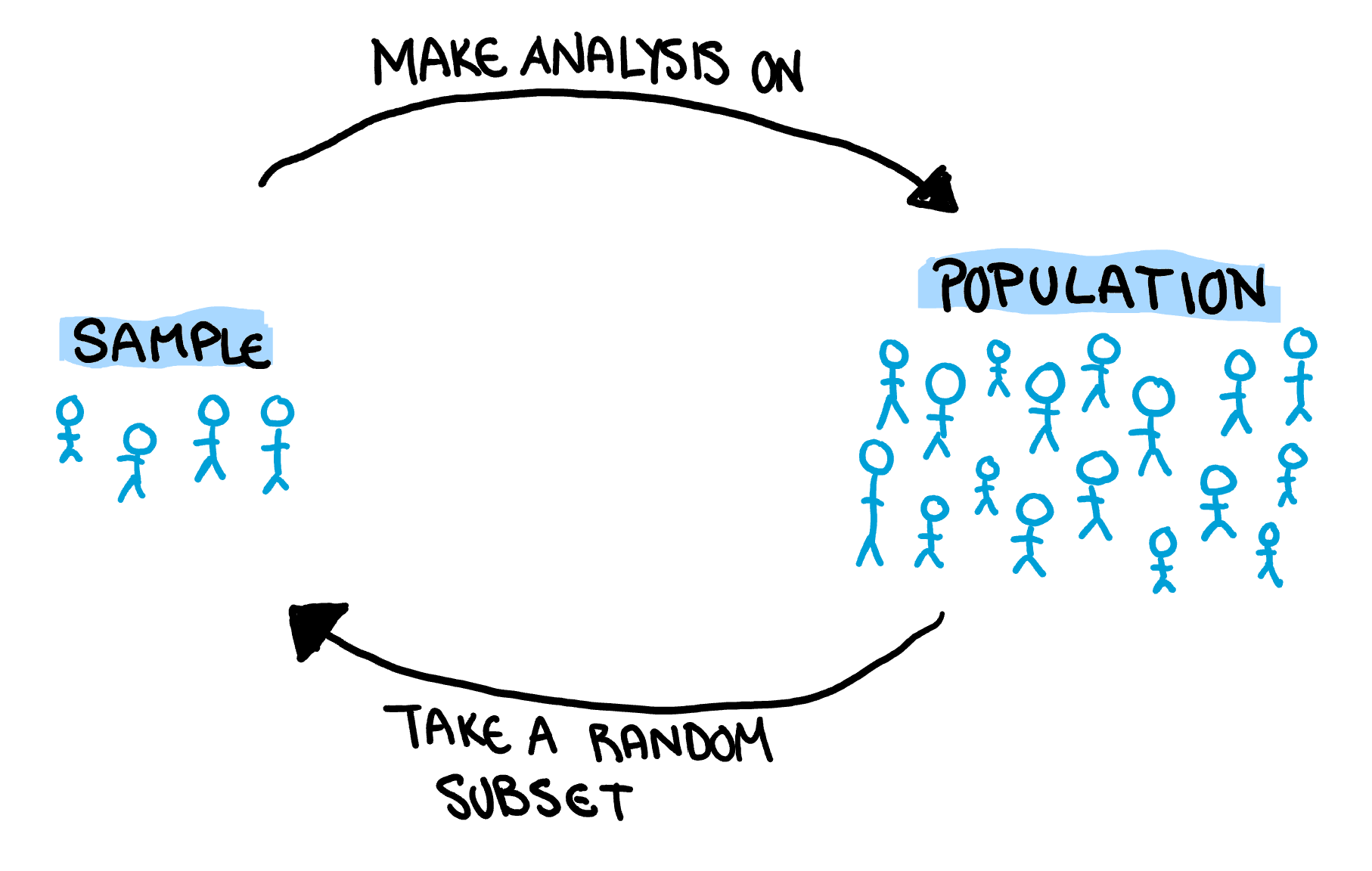
Ok that drawing is literally a cycle. Its just as bad as the explanation. I need to fire my illustrator.
Anyway, this circular explanation, while slightly annoying, is the essence of the population and sample relationship, and why getting a solid grasp on the difference is difficult. Rather than constantly trying to think about populations and samples in this cyclical way, let’s instead think about the implied population from any given sample. Then we can consider what happens when we try to deviate from it.
Part 2: A Case Study In Poor Statistics
Lindy Chamberlain AKA The “Dingo’s Got My Baby” Lady
The “Dingo Ate My Baby” court case is a great example of poor assumptions left right and centre. From a dodgy test for blood to calling in dingo experts from London to the media circus inspiring guilt, the whole thing is an embarrassment to the Australian court system. One of the key arguments against Lindy Chamberlain was that “dingos just don’t attack people”. There was no recorded evidence of a dingo ever severely attacking a person, let alone killing one, and they typically avoided conflict with humans. The story goes, while camping at Uluru, a dingo got into Lindy’s tent, grabbed her baby (Azaria), and ran off into the night. This event had multiple witnesses and logistically made sense. The prosecution argued, that in the 15 minutes Lindy was away from the campsite, she cut her baby’s throat in the boot of her car with nail scissors, stashed the body in a camera bag, hid her baby’s jumpsuit in a dingo lair, used a vial of blood to sprinkle some around the tent, and then went back to the group at the campsite. All in 15 minutes and without getting a drop of blood on her. Seem like an insane story? Well just like Sarah Clark, Lindy Chamberlain was found guilty. During the trial the prosecution had two main points that directed the jury towards a guilty verdict (ignoring the media’s influence) which were both a huge miscarriage of justice and a great case study in a poor jump from a sample to a population.
Prosecution Point 1
“Dingos Just Don’t Attack People, and If They Did, It Wouldn’t Look Like This”
The original coronial inquest for the dingo ate my baby case agreed that Azaria was probably taken by dingos. It wasn’t a far fetched idea that the largest predatory mammal in Australia would eat a small weak animal left alone. Dingos were always wild animals, but they had never attacked people before, and this is a large reason that the criminal trial made it’s way to the courts. The Northern Territory police were dissatisfied with the original coronial inquest and had a second inquest done by sending photos of the baby’s jumpsuit to someone in London who said that the incision around the neck of the jumpsuit implied a cut throat. The jumpsuit of Azaria was mostly in tact except for the top button of the jumpsuit. Something many claimed did not line up with a dingo attack. This part of the argument boils down to “Look, we’ve never seen a dingo attack before, BUT IF WE HAD we’re pretty sure it wouldn’t look like this”. Despite only having a sample of dingo behaviour that included no attacking of people, we used it to understand how they would attack people. In other words, the sample size was too small to capture this rare event, but even so it was used to understand a rare event, expanding beyond the limitations of our data.
Where did this Data Come From? Is My Sample Big Enough?
If we have a sample, it needs to be large enough to be an accurate representation of whatever population we are trying to understand. How large is large enough? It depends. For a rare event such as a dingo attack (there are surprisingly few, feel free to google it), you need a VERY large sample. With too small of a dataset the estimated probability of a rare event goes from improbable to impossible. Additionally, regardless of the size of our sample, we cannot use it to understand events that it has no representation for. Sample size is one of the most commonly cited problems in research critiques, but the problem goes much deeper than that. Most statistical tests (each of which have their own assumptions) typically rely on the sample to be REPRESENTATIVE of the population. Which means it needs to be large enough to capture the rarities of the data, and be an accurate, random sample of that population. Usually as statisticians we focus on averages, but outliers have their own value in of themselves. There are two main questions we should ask about our sample, and the prosecution should have asked about dingo attacks.
1. What is this a random sample of?
If you have reason to suspect there might be a difference between all dingo attacks, vs the dingo attacks we know about we cannot fairly say we know the real probability of something like a dingo attack on a person. To think about what we have a sample of, we need to ask what might cause bias, correlation between observations, ect.
2. Is this sample big enough?
This is usually important for reliability in our understanding, but that is even more important when trying to figure our if the event we are looking at is impossible or just very rare. Even if our sample is big enough to be representative it also needs to be big enough that we can reliably understand its relationship to other factors. 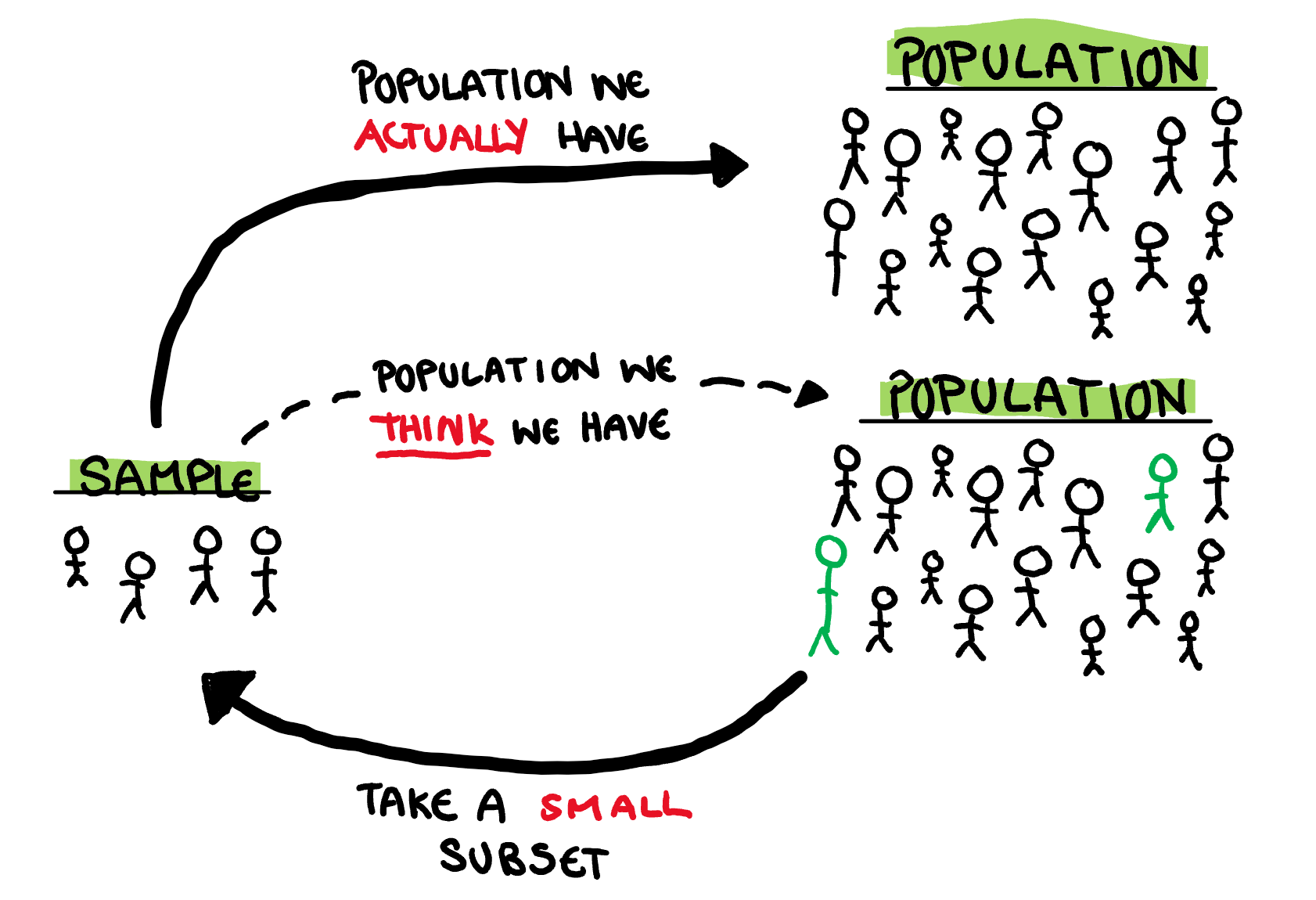
Prosecution Point 2
“This is Baby Blood In Your Car… We Think”
One of the strongest pieces of evidence (still circumstantial which makes the guilty verdict even more embarrassing) was forensic. Basically a test for fetal hemoglobin in the boot of the Chamberlain’s car had it lighting up as a baby blood fountain. What was not discussed at the time of the trial, and what actually later played a key role in exonerating Lindy Chamberlain, was that this test is not conclusive at all. If you want to use the positive results to directly implicate blood, we need to assume the absence of all the other sources of a positive result. Interestingly, one of the substances that could give this test a positive was copper dust. The Chamberlains lived in Mt Isa, a copper mining town. This case of bad science is a perfect example in drawing the wrong conclusions from a sample because our assumptions of whatever method we were using were not fulfilled.
Context is Everything
Every time you do any kind of statistical test, you bring with it a suitcase of assumptions. The type of data, the relationship, ect, ect, most of which goes overlooked. To perform a statistical test without all the assumptions met isn’t a crime, but we need to understand what happens to our results when they are not met. If you are sitting there thinking “oh well that’s just for inference, not for prediction, I’m safe” guess again chump. The issues in assumptions of method and model can mess with your predictions as well.
Lets look to epidemiology to understand this further. The most basic model for prediction infection for diseases is the SIR (susceptible, infected, recovered) model. Basically it just says here is the number of people who could catch the disease, here is the number that have it, and here is the number that have previously had it. The model, while useful, makes several assumption about the interaction of people that are not realistic. For example, by assuming everyone is equally likely to interact with each other and equally likely to catch the disease, it ignores the nuance of social groups. The model has shown before that a high infection rate caused by a single susceptible social group, will lead to massive over prediction for the whole population. 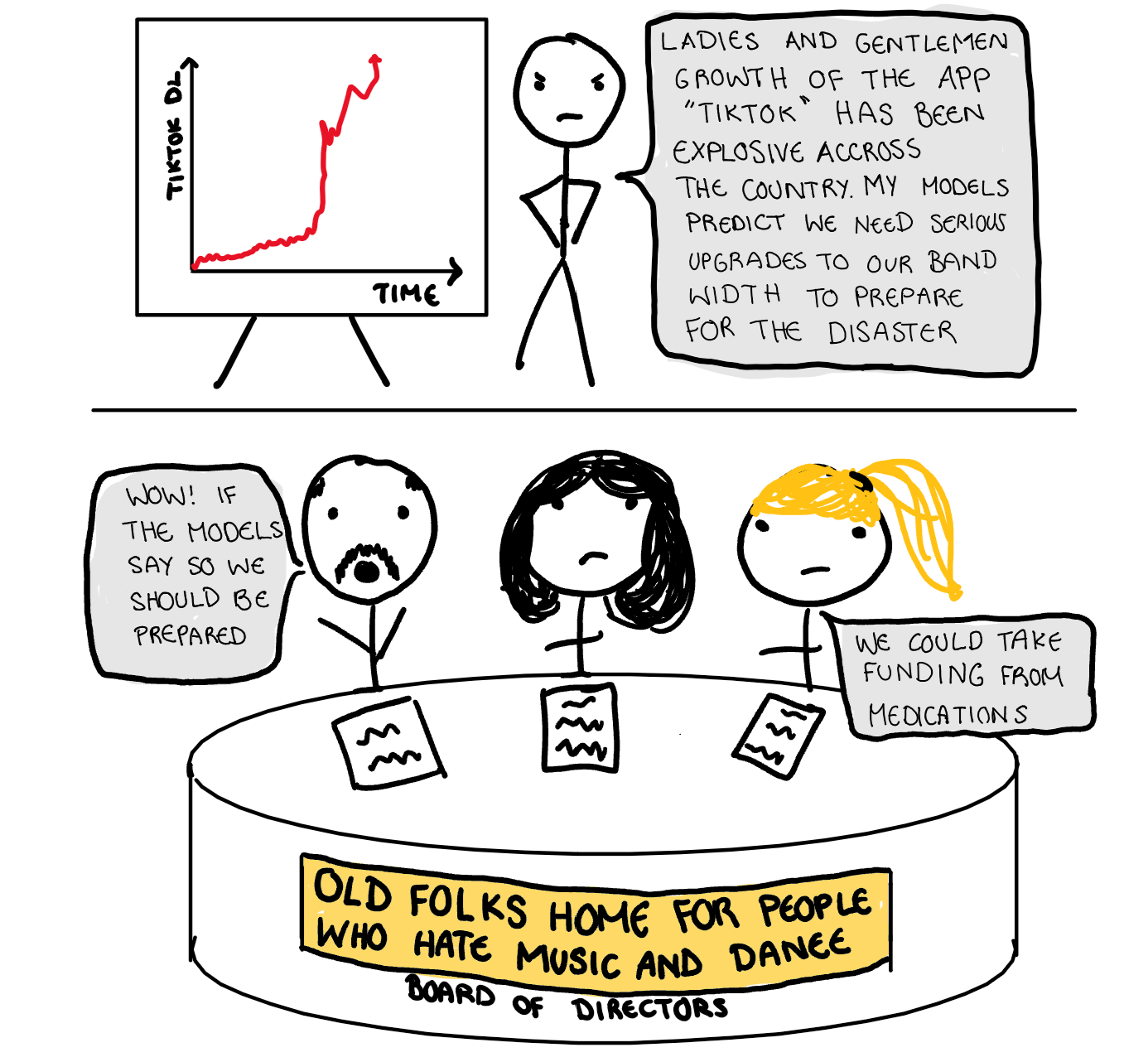
This leads me to the third important question you should ask yourself when trying to understand what conclusions you can draw from your sample.
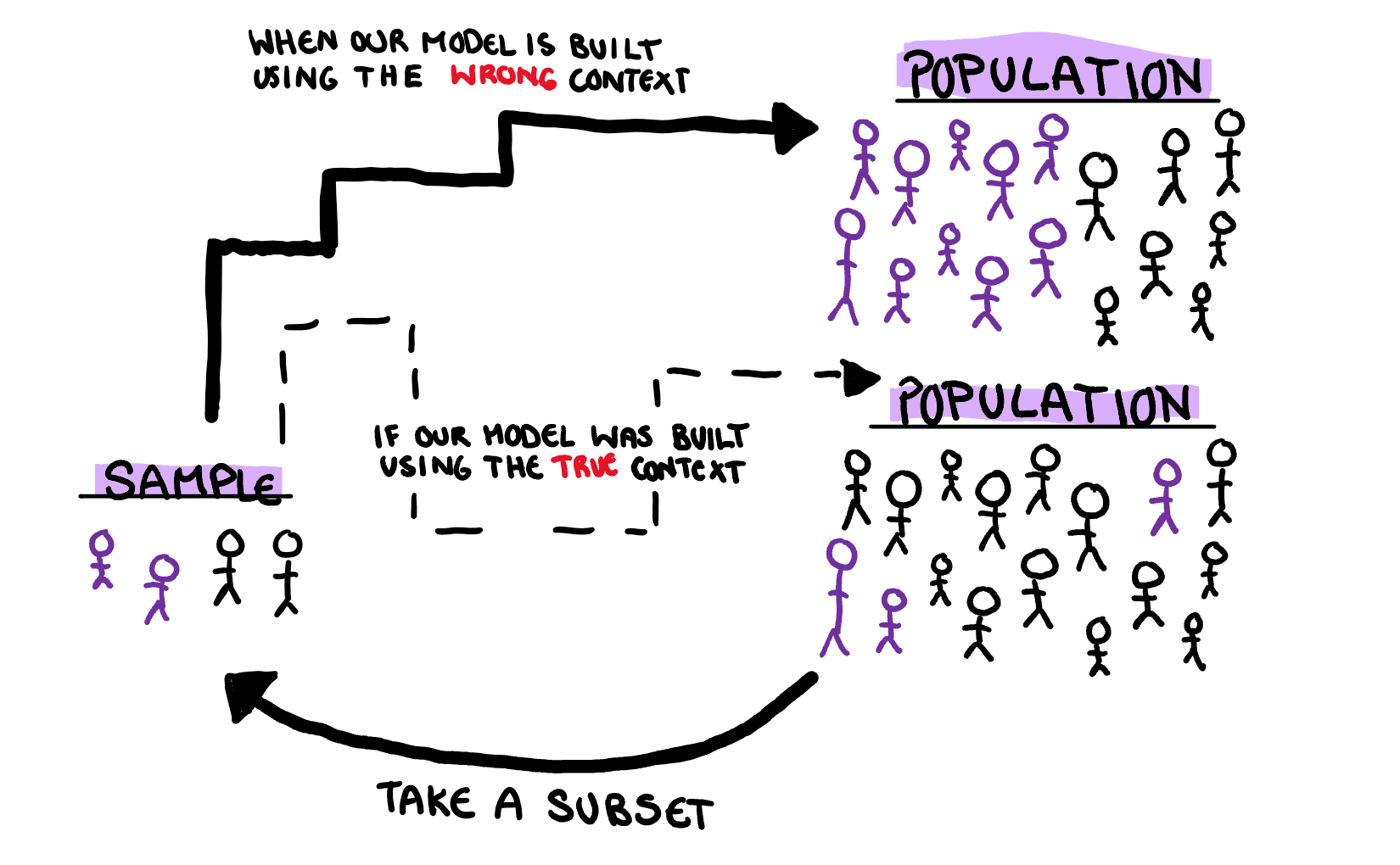
3. What are the assumptions of my model, and what happens when they are violated?
This questions essentially follows after the other two, and is slightly different. Now instead of asking a question about the sample, we are asking a question about the underlying variables. This both gives us the ability to construct models that are more accurate to the problem at hand, and understand the context in which our statistic models might fail. Assuming our current sample’s trends will expand beyond the limitations of the data is a fatal flaw of extrapolation.
In Conclusion
Both statisticians and legal prosecutors make mistakes all the time, that being said, sometimes they were avoidable. If we simply take a step back, and assessed the limits of our conclusions we could stop many overconfident predictions, and wrongly accused mothers. Before doing any kind of analysis there are a handful of questions we should ask ourselves. What is my data a sample of? Is my sample large enough to capture what I’m investigating? Is my model making ridiculous assumptions about my variables? Is murder REALLY the most likely reason for a fragile baby to die? Ok, maybe less of the last question for statistics, but the other three for sure.