Using the Bachelor to Understand Permutation Variable Importance
The season of the bachelor is upon us, and what better way to celebrate my love of drawn out reality TV, than to use it to explain permutation variable importance in the random forest model. For those who are not familiar, The Bachelor is a dating show where each week female contestants are eliminated when they do not receive a rose during the rose ceremony. The winner is famously difficult to predict, and many complicated factors (screen time, number of dates, ect) mean our variables are ever evolving through the season and difficult to use in analysis. Today we will not be predicting the winner of the bachelor (as fun as it sounds) but rather, we will use The Bachelor as the basis of an example in calculating variable importance.
What Matters Most When Choosing A Partner
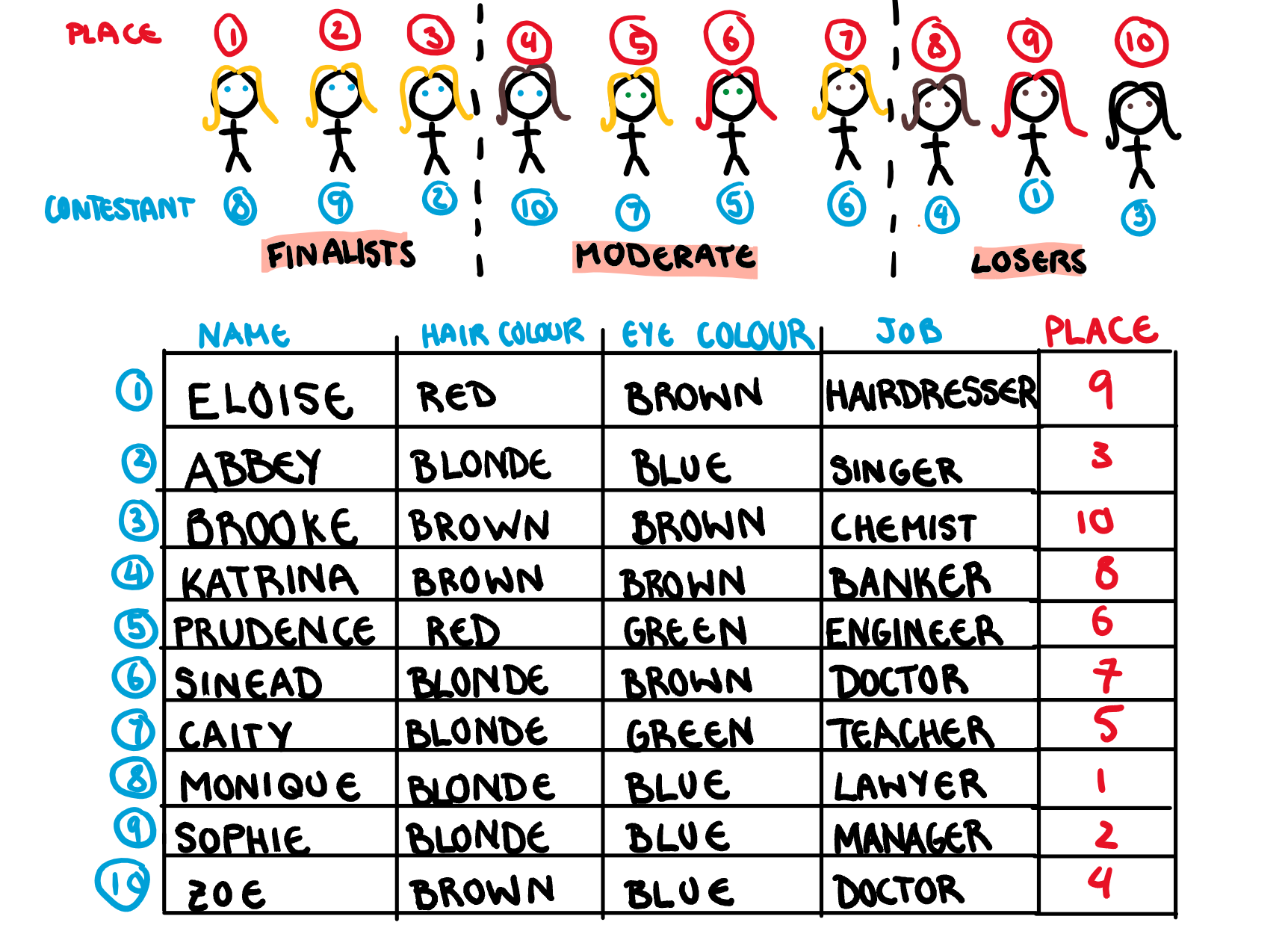
Anyone who has viewed the show for many years starts to notice a trend in the girls who always make it to the end of the competition. In the image below I have circled the top six participants from last year’s season.

Notice anything? The girls at the end of the bachelor are overwhelmingly blonde. Of course regular viewers would notice other things too. Like how every season has a group skydiving date that ends with one of the girls crying, overcoming her fear, and getting extra time with the bachelor (when I type this out the show sounds stupid). However we are going to focus on the hair, specifically how we can find out how important hair colour is in separating the winners from the losers.
Introducing Our Bachelorettes
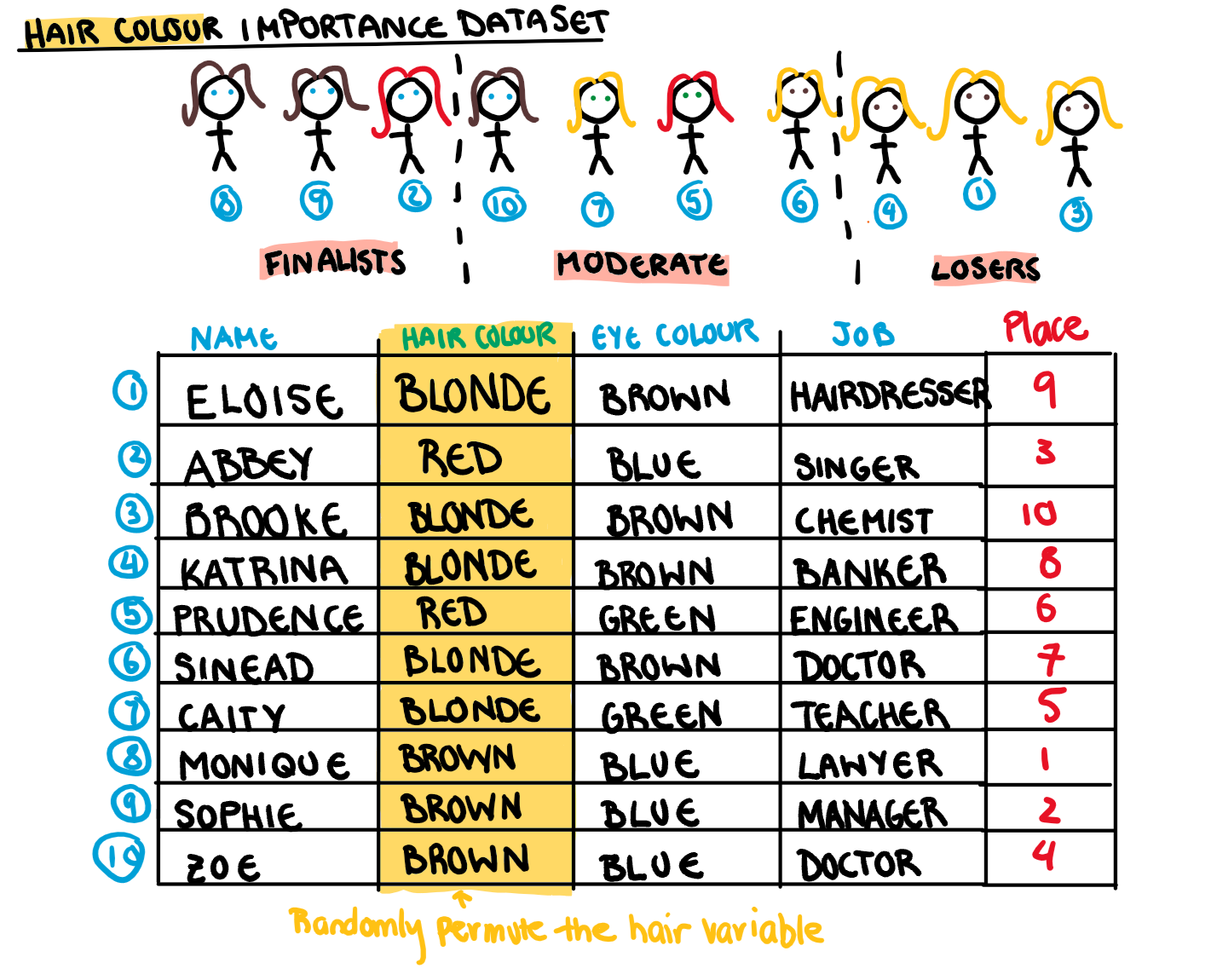
For our illustration, let’s make an example competition that consists of 10 people, broken down into their most arbitrary characteristics: name, hair colour, eye colour, and job.

Obviously the real winner isn’t chosen on these characteristics alone, but this is a fake example and my fake bachelor is a shallow guy. First we give all the girls a final position in the fake competition, and assign them to one of three groups: finalists (top 3), place moderately (middle 4), and losers (bottom 3).
A Normal Random Forest Model
Before we can even look at variable permutation, we need a random forest model. If you need refreshing on how they work, a random forest model will take B bootstrapped samples, and build a tree for each. Usually, just by chance, about a third of the contestants will not be used to build each tree, these are the out of bag contestants.
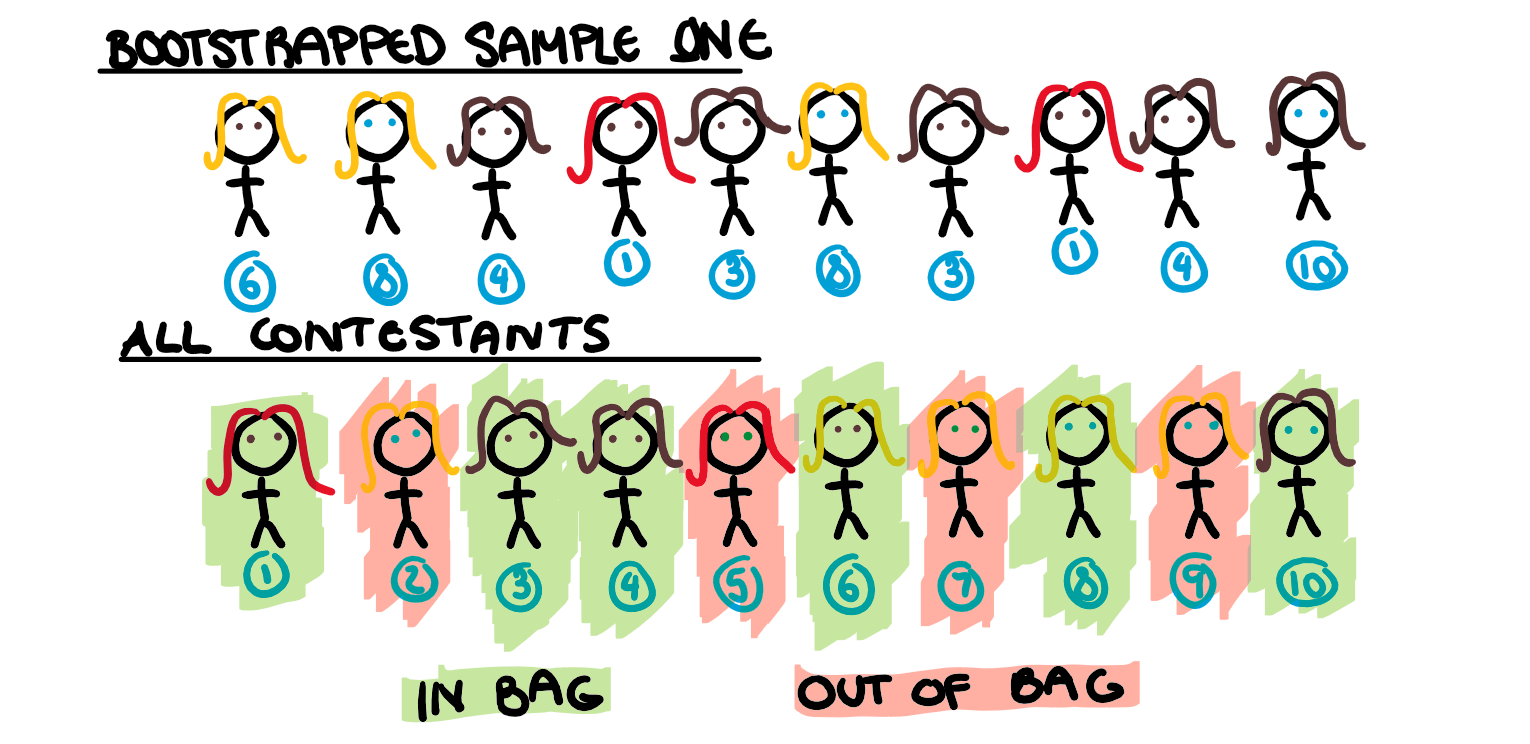
Typically, for more complicated data sets, random forest models use a random subset of all the predictors at each node. However, Since we only have 3 predictors, we will ignore that for this example (it won’t have any major influence on our results). This model will have multiple trees, but for simplicity, we are only going to look at the first tree in depth, which is illustrated below.
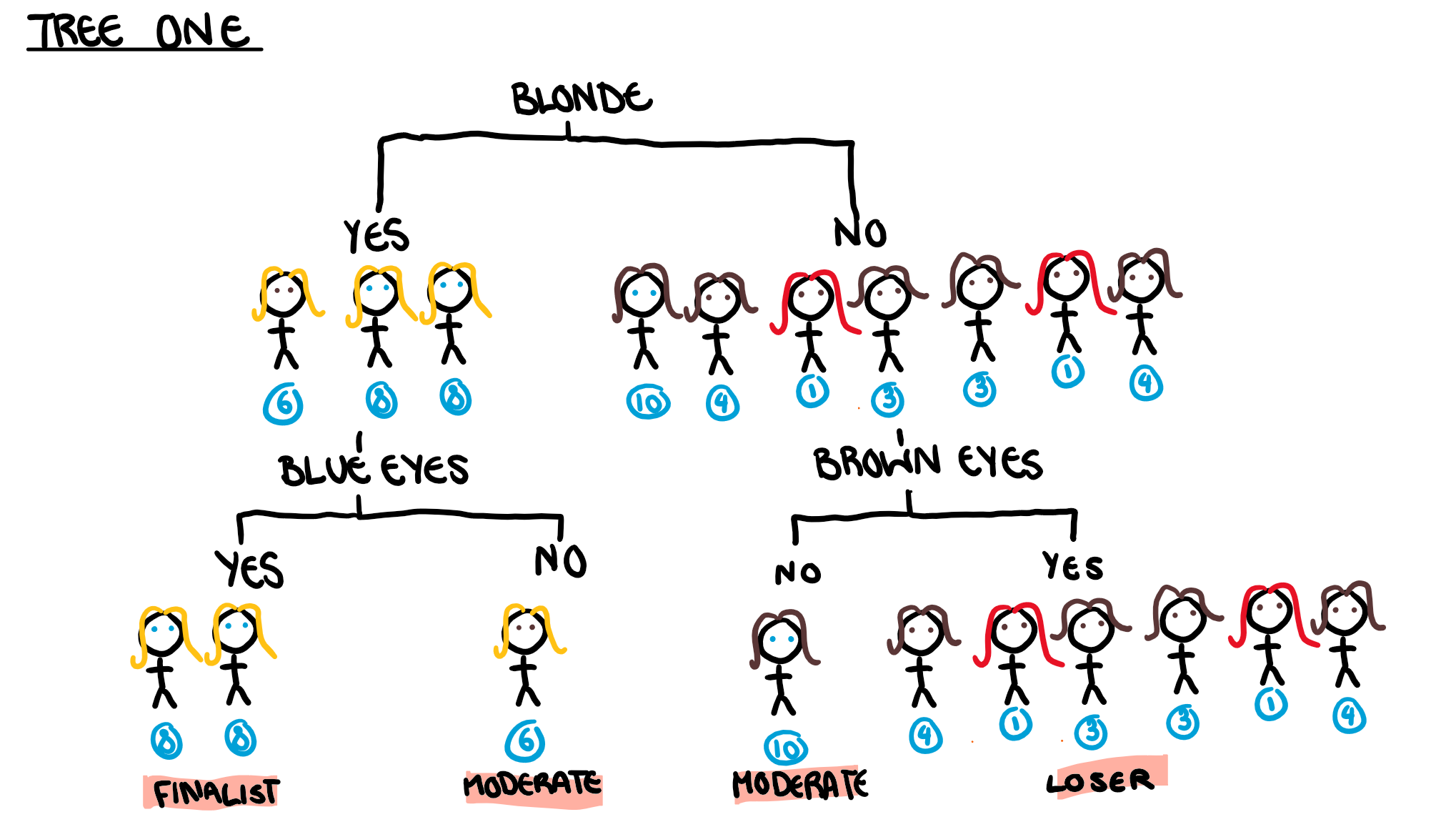
Contestants 2,5,7, and 9 are our out of bag contestants and so were not used to build the tree. Running these four contestants through the tree we get our out-of-bag (OOB) error.
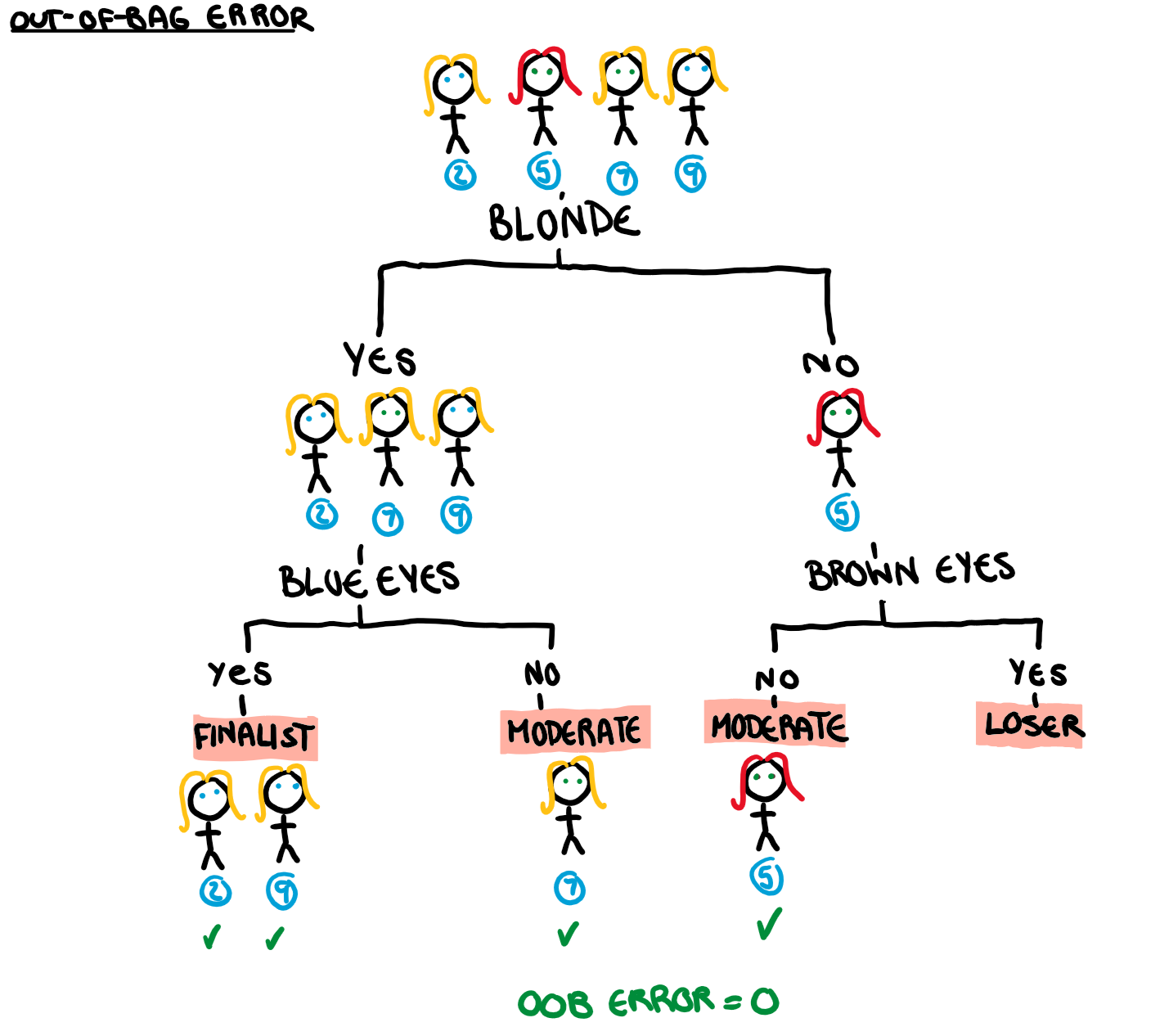
Now at this point we have a bootstrapped sample, a tree, and an OOB error for all of the B trees in our forest (but we have only looked at the first in depth). This is the basis of a typical random forest model, and it is also what we will use as a point of comparison when we permute our variables.
Permutation Variable Importance
To calculate the importance of a variable (in this case hair), we randomly permute that variable among the observations. This creates a new dataset where all the variables are the same EXCEPT for the one variable we are checking. So for the bachelor example, the girls have all the same characteristics as before except their hair colour is randomised.
Rationally, we can tell that if our Bachie isn’t using hair colour as a key decider for his life partner (as we would hope), randomising that variable would have no effect on the girls position in the competition. People getting divorced over dyed hair is no way for a society to function. Again, we calculate our OOB error, using the tree above and contestants 2,5,7 and 9. However, we now take our predictors from the table with the permuted hair variable.
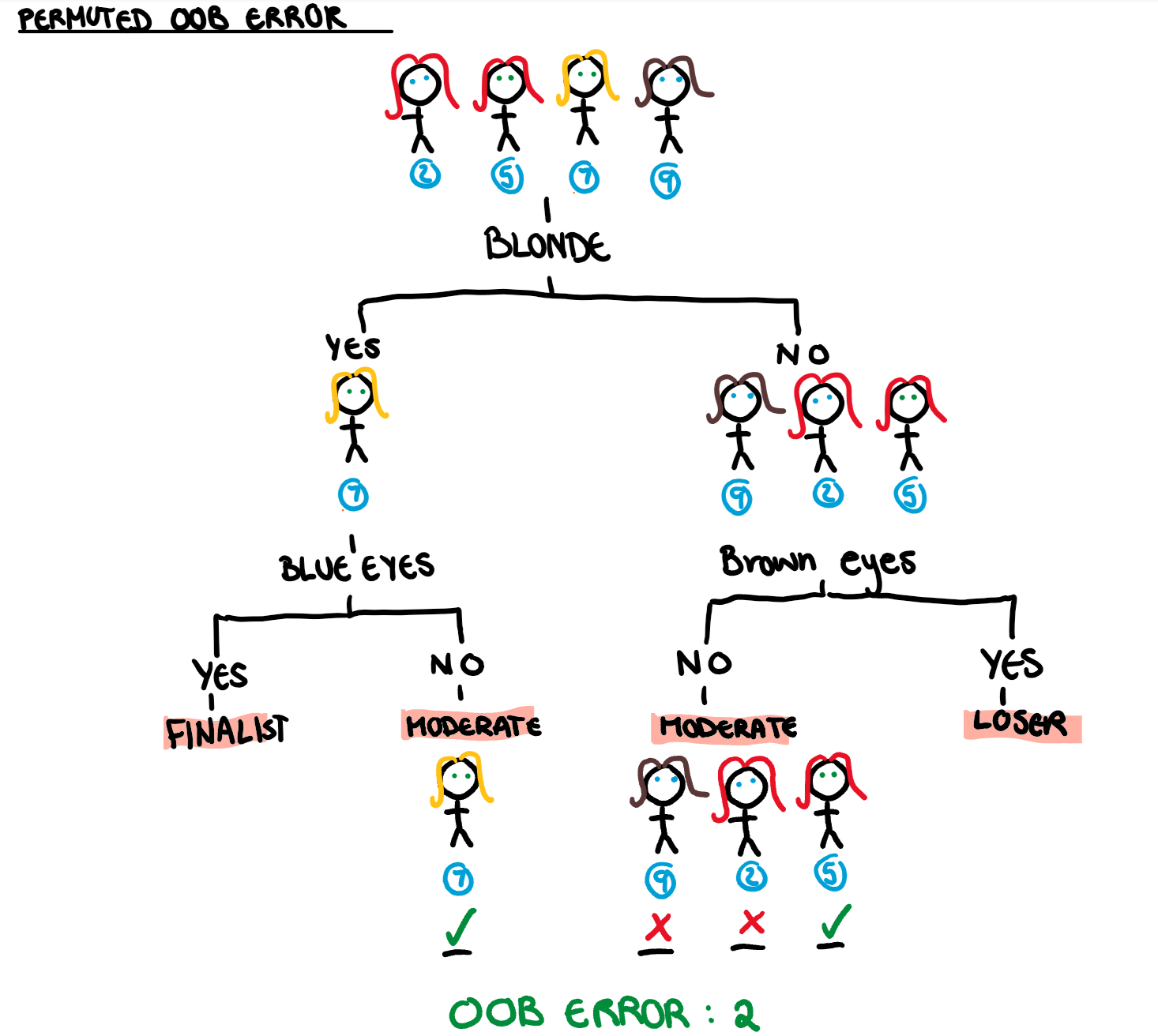
This gives us an OOB error for the version of the bachelor where love is colour blind. The difference between the first OOB error and the OOB error for the permuted observations will give us the importance of hair colour in the first tree. We repeat this calculation for all trees in the forest, and take the average to find the overall variable importance. That in a nutshell is how we calculate the permutation variable importance.
Final Comments Before we Leave the Mansion
It easy to see the logic behind this method of calculating variable importance. If we are essentially rolling a dice to decide a variable, it shouldn’t be useful in making predictions. If previously that variable was important, we have caused serious damage to the predictive power of our model. While this isn’t a complete computation in variable importance (since we only calculated it for one tree and one variable), it’s purpose is to take a look under the hood of the process, and, hopefully, into the heart of our bachelor.

This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.